More than seven years ago, I wrote an article titled Rocks Don’t Need to Be Backed Up.
I based the article on an Egyptian obelisk my wife and I saw in New York City’s Central Park. Here is the picture used in the 2009 article, in which you can clearly see the 4,000-year-old object:

Note that you can clearly see the hieroglyphics, and thanks to the Rosetta Stone, you can actually translate what it says into a modern language. But until finding the translation on the Rosetta Stone between ancient Egyptian hieroglyphs, Demotic script and Ancient Greek, no one knew what these hieroglyphs meant for roughly 1,800 years. Non-optimal, as I like to say.
So while in France this year with my wife, I saw another Egyptian obelisk and thought it was time for an update:

Clearly, there is some significant data loss on the above rock, so I guess some rocks do need to be backed up, as anyone who’s ever visited an old graveyard can attest.
What does this mean for data protection?
Hieroglyphs are pretty easy compared to what we have today. Something as simple as file formats, many of which are used on Microsoft OS and others, are a nightmare. Here are just a few of the ones starting with the letter A:
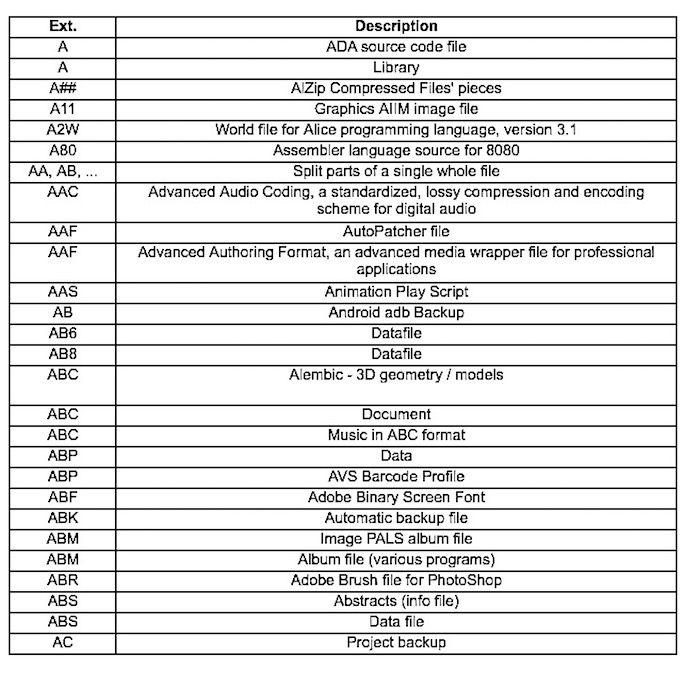
There are 275 beginning with the letter A alone, 180 for B, and so on. You get the point.
In 20 years, much less thousands of years, how is anyone going to figure out what data is stored in each of these file formats? Of course, some of them are open source, but many are not. And even for open source, who is going to save the formats and information for a decade or more? I cannot even open some MS Office documents from the early 2000s, and that is less than two decades. The same can be said for many other data formats. There are self-describing data formats such as HDF (Hierarchical Data Format), which is about 30 years old, but outside of the HPC community, it is not widely used. There are other self-describing technologies in other communities, and maybe like HDF they could be used for virtually any data type. However, everyone wants what they have, not something new or different, and NIH is what usually happens in our industry.
A modest proposal for data continuity
Unlike Jonathan Swift in his 1729 satire, I am going to propose something serious—but it approaches comedy when I consider the odds of it ever happening. I would like to suggest that an ANSI, ISO or IEEE committee come together and create an open standard for self-describing data. This format must encompass all other formats that exist today in weather, multiple medical formats, geospatial, genetics and so on. This working group could meet and get agreement across various industries in pretty short order, I believe. Just like wrapping files that are already wrapped. This clearly doesn’t solve the whole problem with its long-term issues, but it does get us to a common agreed format. This could also be used for any other file type like a jpeg.
This proposal comes with some significant problems, not the least of which is the fact that getting the right people in the room will be difficult at best. I do not think the issues will be as much technical as much as getting people to think of the value beyond their industry.
The next big problem will be the cost for each industry. Take magnetic resonance imaging (MRI), something most of us over the age of 50 are familiar with. How long would it take GE and Toshiba (both large MRI manufacturers) to change all their machines to support the new format as part of the output? How long would it take to re-format all of the data they have collected (I do not know about you, but I have a number of MRI scans of my various joints)? It is going to take years if it ever happens (more likely decades). Even if people wanted to convert, what would it cost to read from archive, CPU power, I/O bandwidth and rewrite to archive, and the personnel cost too? Basically, it is never going to happen.
The only possible outcome is that there would be a cutover point where old data in the archive is read when needed and any new data is under a new format. Others will say, “Who needs a new format, as our format is open and standard?” But multiply that across a thousand file formats and you begin to grasp the extent of the problem. This does not end well for big data analysis of the future, where people are looking at relationships we have not even thought of with historical data. What will be lost if not all data can be read?
Back to Egyptian data loss
I am not sure why the first obelisk was so well preserved and the second one was not. There can be lots of reasons for data loss. In the case of the obelisk, sand storms and water are just two examples. The fact of the matter is that we would not be able to read the first one had it not been for the Rosetta Stone and the three translations on the same rock. So there are two points of potential data loss for future generations trying to read our data:
- Data failure, like the second rock
- Our ability to translate the data, like the first rock
Because it is about data protection, preventing data loss in the case of the rock worn away by time is reasonably simple with multiple copies in multiple places, with checksums and checking on each copy. Translation, on the other hand, is far more difficult. Besides having format winners and losers, there are issues of formats changing over time to the point that they quickly become unreadable. There are open source formats like PDF and standard formats like jpeg 2000, but even those might change over time. And how long they are backward-compatible is up to the group of people who control the standard.
The bottom line is our future depends on people who might or might not be thinking about the past and the future and the importance of data preservation. What about all of the other formats, and what about formats like Microsoft Word that have had compatibility issues over time? People need to start thinking about data formats, and the time is now given the growing enormity and complexity of the problem. The technology problem is not difficult, but the politics surrounding the problem are currently insurmountable. We seem headed for massive data loss unless we act.




