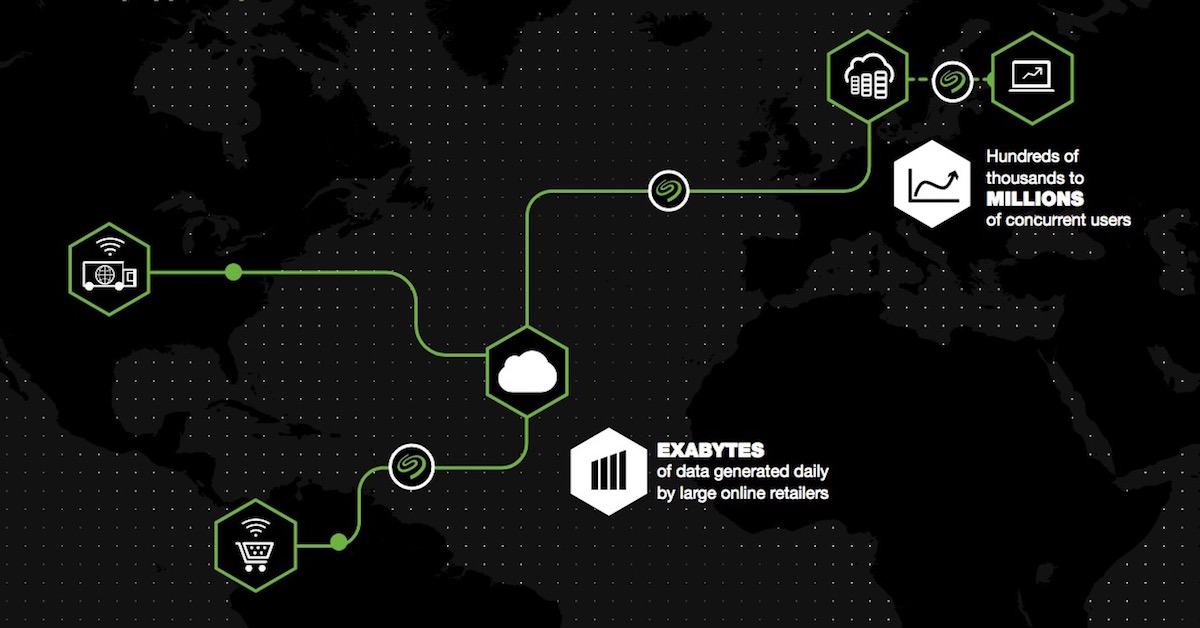
Big data is generally defined by the three Vs – volume, variety and velocity – but it is important to understand how those terms apply to technology decisions. Volume is often the first issue that emerges in big data discussions as companies realize they are managing much more information than their traditional solutions can handle. This places more emphasis on capacity and drives demand for cost-effective methods of expanding the data center, including cloud storage.
However, the challenges associated with volume extend beyond the files themselves. As Data Center Knowledge contributor Krishna Kallakuri noted, these massive volumes also create a lot of metadata, making traditional file systems inefficient and raising the value of object-oriented platforms. Fortunately, cloud technology has been able to handle this issue by offering an unprecedented level of scalability.
As business delve deeper into analytics, velocity typically grows in prominence. As Kallakuri suggested, there is an ever-increasing demand to perform analytics in real time. This means that latency between where the data is stored and the analytics solution is unacceptable for many organizations. The National Cancer Institute has attempted to solve this problem using cloud storage. By keeping data in a third-party environment, researchers can access cancer information quicker and easier than they would be able to if they had to download it.
Access and security
Although big data creates challenges from an information management perspective, there is also risk involved simply because analytics involves bringing multiple data sets together (variety). Kallakuri suggested that this requires a higher degree of security all the way down to the storage hardware level. At the same time, the other components of big data (volume and variety) must be addressed.
The security issue is further complicated by the fact that many big data programs can be accessed from anywhere. This can make it more difficult to protect against unauthorized users if organizations lack authentication protocols.
Writing for The Guardian, IBM's Gretchen Marx recently explored the role of identity and access control mechanisms in cloud environments. Such features are essential for reducing risk, and cloud customers are increasingly turning toward providers that enable these controls and provide visibility regarding who is accessing important data.
Context-based access control is one feature that Marx highlighted in particular. This would give IT administrators more visibility over when data is accessed and more power to determine where it can be accessed from. For example, a doctor may be able to read and edit all patient files when logging in from an office computer during the workday but would need to go through more intensive authentication measures when logging in from a personal device.
"With employees, customers, business partners, suppliers and contractors increasingly accessing corporate applications and data with mobile devices from the cloud, protecting the edge of the network is no longer enough," Marx wrote.
Addressing customer security concerns depends heavily on a multi-faceted approach that covers endpoints as well as data-centric solutions. For example, in addition to access controls, encryption can serve as a valuable tool to mitigate the risk of a hacker breaching the system
As organizations invest in cloud solutions to fulfill a wide range of needs and begin launching their big data initiatives, sophisticated security mechanisms will likely produce better return on investment. Cloud providers can be proactive by promoting transparency in their service-level agreements and clearly outlining how they would handle a breach if one did occur.