New editorial content on the news portal, Datanami addresses an important issue facing the enterprise – that of meeting the demand for larger data analytics. In the piece ‘Accelerating Hadoop® Workflows to Yield Greater Application Efficiency‘ the question is raised about whether Hadoop will continue to reliably scale and serve as the primary workhorse for enterprise production level data analytics. In this blog synopsis we address the highlights of the answer…
- “…many organizations utilize Hadoop and big data analytics to make informed business decisions…Hadoop Distributed File System (HDFS) was designed to create data locality as is
documented in the HDFS Architecture Guide with the statement “Moving Computation is Cheaper than Moving Data.” - “This approach was optimal at the time when network bandwidth was much lower (typically 1 Gbit/sec Ethernet (GbE)) than it is now (10 GbE, 40 GbE, or even faster with InfiniBand).”
- “The real problem with HDFS is not theoretical scale, it is pragmatic usable scale in time. This is due to the unacceptable amount of
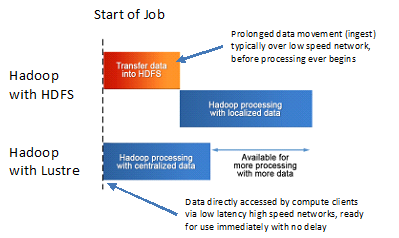 time required to move (ingest) data into and out of traditional HDFS-based Hadoop clusters, especially when using low-bandwidth networks.”
time required to move (ingest) data into and out of traditional HDFS-based Hadoop clusters, especially when using low-bandwidth networks.” - The figure to the right shows the impact associated to the long transfer of data into HDFS (ingest) before Hadoop processing begins. It also demonstrates that Lustre enables Hadoop processing to begin immediately since data is directly accessed by compute clients over low latency high speed networks.
- “Borrowing from the best available high performance computing (HPC) capabilities, Lustre provides the means to store, process and manage all of your enterprise critical big data within one high performance data repository that linearly scales in performance throughput directly in proportion to your problem size measured in data capacity.”
- “Rather than the HDFS design assumption to minimize network traffic during processing, Lustre takes the opposite approach leveraging proven state of the art supercomputing technologies that represent a true break-through on how to extend the useful life and scale of enterprise critical Hadoop applications.”
- “…this means your enterprise-critical big data stays in one place within the high performance data repository, ready for use immediately with no delay and no more prolonged data movement (ingest) before and after processing.”
This article is the first in a series which highlights Hadoop with Lustre, which enables nearly unlimited Hadoop scale, while providing the means to attain high reliability, sustained production levels, and compatibility with your Hadoop data analytics environment.
To learn more on how to make these gains a reality, check out Seagate’s Hadoop Workflow Accelerator or visit us at www.seagate.com/hpc.