With the announcement of Seagate’s support for the Redfish 1.0 release, there has been much interest in understanding how this new API standard improves customer and partner ability to programmatically manage Seagate systems. Let’s dive into the standard by first exploring its object model:
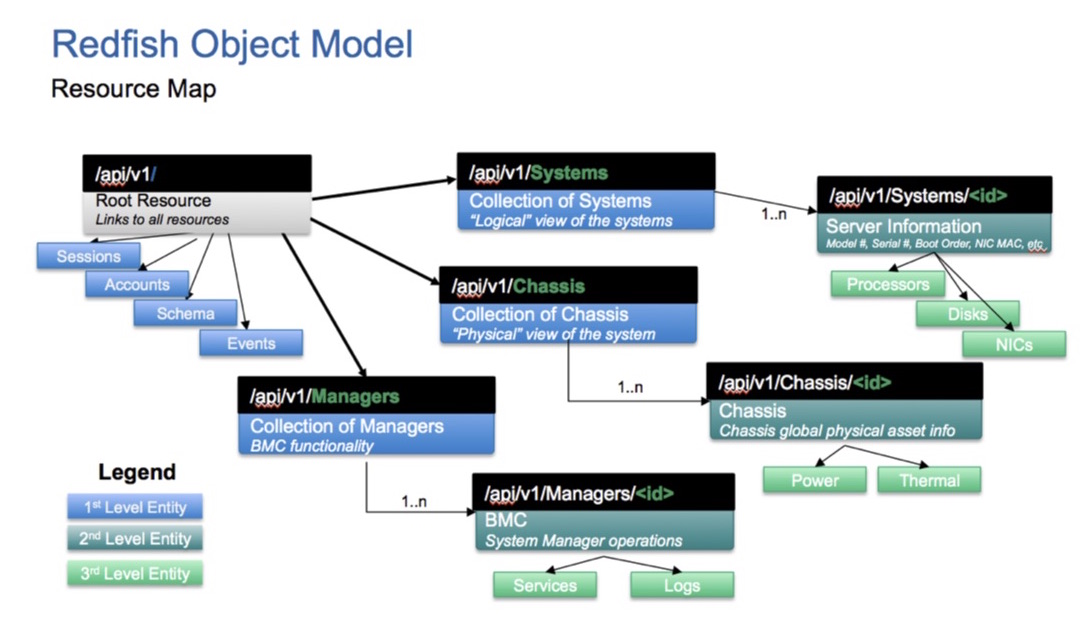
For a better understanding of how these collections might be realized on a given hardware system (like a Seagate Backup and Recovery Appliance), you’ll want to take advantage of mockup available in the Redfish Resource Explorer, which gives an example of what a simple implementation might look like within a single server.
Why a new standard? Most of you are aware of these inherent security concerns with the use of IPMI, but it’s interesting to see an official statement nonetheless – https://www.us-cert.gov/ncas/alerts/TA13-207A. These concerns capture the incentive for the industry to move to more modern management protocols from a security perspective.
Let’s talk about some of the specifics. The hypermedia design of Redfish is aligned with well-established cloud APIs. It follows CRUD and RESTful design principles and incorporates meta-data conventions established in the Open Data Protocol standard for enhanced self-description. This means that system administrators will find Redfish familiar and easy to implement. For example, assets instrumented with the Redfish standard are accessible with a standard web browser and can be interacted with by adding a REST browser plugin. Python, Java and other JSON friendly processing environments have tool ecosystems that are ideal for Redfish integration. What’s more, Redfish is self-describing, allowing generic OData-enabled clients like Microsoft PowerShell and Excel Power Query to interact directly with a Redfish service. And Redfish delivers this functionality on a “bare metal” server; no operating system or cumbersome agents are required.
This article originally appeared on Lee Calcote’s blog.
About the Author
Lee Calcote is a Director of Software Engineering within the Seagate’s Cloud Systems & Solutions organization and is focused on strategy and development of software solutions for hyper-converged infrastructure, software defined storage (SDS) and software defined data centers (SDDC).
Follow Lee Calcote on Twitter or read his blog at Ginger Geek.