Sztuczna inteligencja jest coraz częściej wykorzystywana w różnych branżach i zastosowaniach, a jej skuteczność zależy od niezawodnego działania. Niezawodna sztuczna inteligencja stała się poszukiwaną walutą biznesową.
Budowanie godnej zaufania sztucznej inteligencji opiera się na kluczowych elementach, które zapewniają niezawodność danych i wyników. W tym artykule omówimy znaczenie przejrzystości, pochodzenie danych, uzasadnienia, rozliczalności i bezpieczeństwa w kształtowaniu systemów AI, którym możemy zaufać. Każdy z tych elementów wspiera integralność i niezawodność danych, które są niezbędne do zapewniania sukcesu sztucznej inteligencji za pomocą dysków twardych, które stanowią podstawę pamięci masowej potrzebnej do dostarczania tych korzyści w sposób spójny.
Godna zaufania sztuczna inteligencja odnosi się do przepływów pracy związanych z danymi AI, które korzystają z niezawodnych danych wejściowych i generują wiarygodne informacje. Godna zaufania sztuczna inteligencja bazuje na danych, które spełniają następujące kryteria:
- wysoka jakość i dokładność,
- jasna informacja na temat legalności, przynależności i pochodzenia,
- bezpieczne przechowywanie i ochrona,
- transformacje algorytmiczne, które można objaśnić i prześledzić,
- spójne i niezawodne wyniki przetwarzania danych.
Godna zaufania sztuczna inteligencja opiera się na skalowalnej infrastrukturze pamięci masowej, która pomaga w odpowiednim zarządzaniu, przechowywaniu i zabezpieczaniu dużych ilości danych wykorzystywanych przez systemy AI.
Godna zaufania sztuczna inteligencja w dużych centrach danych.
Procesy wykorzystujące sztuczną inteligencję obejmują ogromne ilości danych, które wymagają niezawodnej infrastruktury do skutecznego zarządzania. Aby zarządzać tymi ogromnymi zestawami danych, centra danych obsługujące obciążenia robocze związane ze sztuczną inteligencją są wyposażone w skalowalne klastry pamięci masowej, które zapewniają obiektowe magazyny i jeziora danych. Ta infrastruktura stanowi podstawę całej pętli danych AI, począwszy od pozyskania nieprzetworzonych danych, aż po przechowanie wyjściowych danych z modeli do wykorzystania w przyszłości.
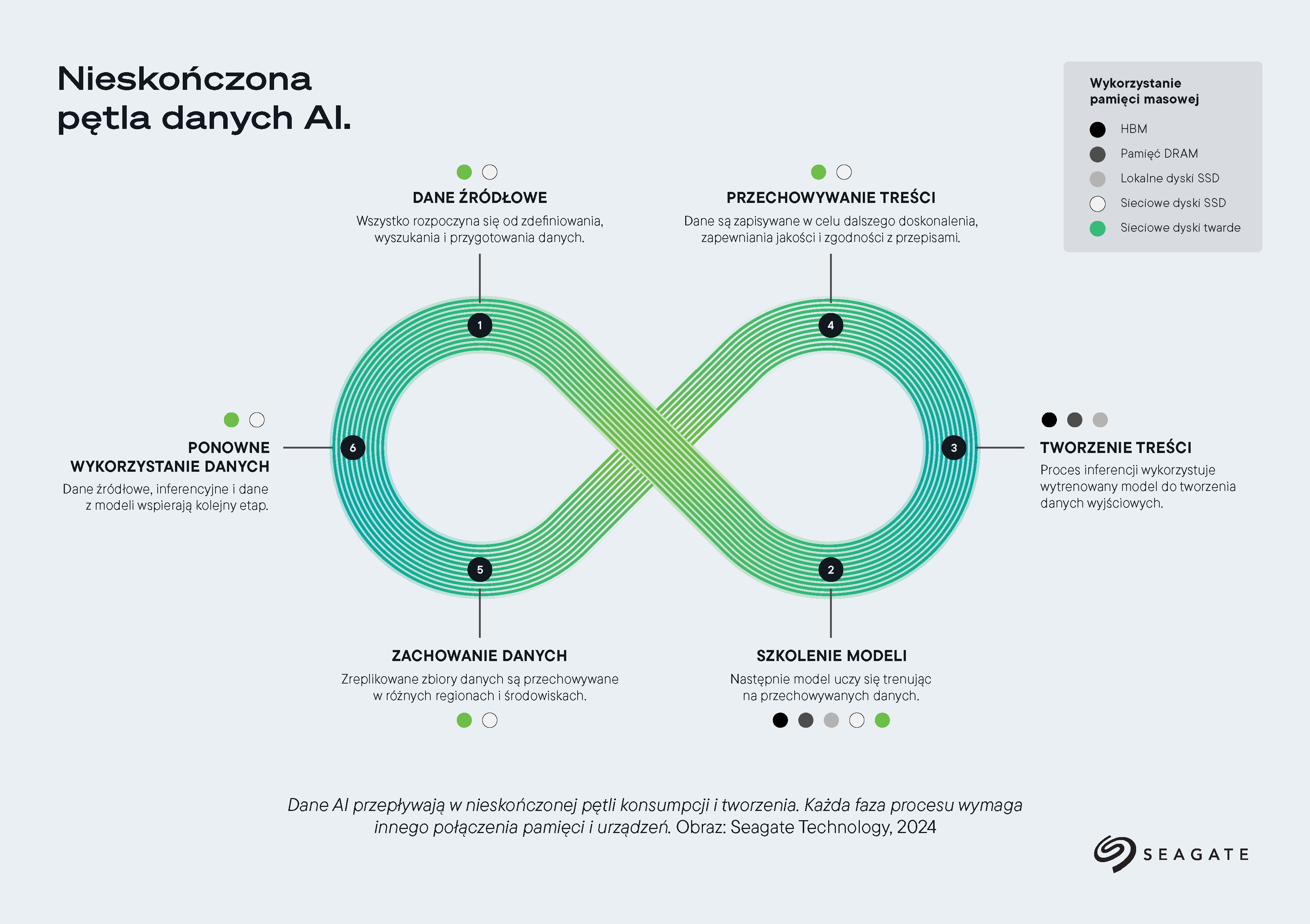
Bez skali i wydajności centrów danych potencjał sztucznej inteligencji byłby ograniczony, ponieważ możliwość przechowania i udostępniania ogromnych zbiorów danych ma kluczowe znaczenie dla właściwego działania sztucznej inteligencji.
W nowoczesnej architekturze zoptymalizowanej pod kątem sztucznej inteligencji warstwy odpowiedzialne za przetwarzanie, pamięć masową i sieciowanie są w zrównoważony sposób zintegrowane ze sobą. Jeziora i obiektowe magazyny danych – często wykorzystujące wiele warstw pamięci masowej – są fundamentem środowisk AI i umożliwiają osiągnięcie wysokiej wydajności obliczeniowej w dużej skali. Infrastruktura pamięci masowej ma kluczowe znaczenie dla zapewnienia systemom AI dostępu zarówno do danych wymagających natychmiastowego dostępu, jak i danych archiwalnych. Architektury przeznaczone do sztucznej inteligencji są projektowane z myślą o ogromnej skalowalności. Równowaga pomiędzy pojemnością i wydajnością pamięci masowej wpływa na zdolność systemów AI do wydajnego działania i zmiany skali w zależności od potrzeb.
Kluczowe elementy godnej zaufania sztucznej inteligencji.
Jednak skalowalne architektury to za mało. Godna zaufania sztuczna inteligencja potrzebuje również elementów, które zapewniają zaufanie: przejrzystości, pochodzenia danych, uzasadnienia, rozliczalności i bezpieczeństwa. Przyjrzyjmy się, w jaki sposób te elementy wspierają integralność procesów produkcyjnych wykorzystujących sztuczną inteligencję.
Przejrzystość: zrozumiała sztuczna inteligencja.
Przejrzystość w odpowiedniej skali to klucz do godnej zaufania sztucznej inteligencji. Gwarantuje ona, że decyzje podejmowane w systemach AI są zrozumiałe, dostępne, powtarzalne i możliwe do skorygowania. Kiedy, na przykład, system AI rekomenduje film do obejrzenia, użytkownik może dzięki przejrzystości zrozumieć uzasadnienie tej sugestii, ponieważ jest ona oparta na przejrzystych danych, takich jak historia i preferencje użytkownika w zakresie filmów.
W centrach danych skalowalne klastry pamięci masowej wspierają przejrzystość, zapewniając zrozumiałe zapisy każdego punktu decyzyjnego w cyklu życia danych AI. Taka infrastruktura pozwala organizacji śledzić dane od punktu wyjściowego, przez ich przetwarzanie, aż do etapu danych wyjściowych, co gwarantuje większą rozliczalność.
Przejrzystość odgrywa ważną rolę w wielu branżach. Trzy przykłady:
- W służbie zdrowia algorytmy AI analizują obrazowanie medyczne, pomagając we wczesnym wykrywaniu chorób. Im bardziej przejrzyste dane, tym dokładniejsza diagnoza.
- W finansach algorytmy transakcyjne szybko przetwarzają dane rynkowe i filtrują je w bardziej efektywny sposób, pozwalając menedżerom portfeli lepiej zrozumieć i zoptymalizować strategie inwestycyjne. Wiarygodne dane mogą poprawić zwrot z inwestycji.
- W przetwarzaniu języka naturalnego (NLP) chatboty odpowiadają na zapytania klienta. Przejrzyste pochodzenie danych daje gwarancję rozliczalności przedsiębiorstw.
Przejrzystość przyczynia się do większej rozliczalności, ponieważ umożliwia poznanie źródeł danych, decyzji i wyników modelowania.
Pochodzenie danych: śledzenie źródeł i wykorzystania danych.
Pochodzenie danych rozumiane jest jako zdolność do identyfikacji proweniencji i wykorzystania zestawów danych w całym procesie AI. Ma to kluczowe znaczenie dla zrozumienia procesów decyzyjnych w modelach.
Na przykład, w zastosowaniach wykorzystujących sztuczną inteligencję w opiece zdrowotnej wgląd w pochodzenie danych pomaga prześledzić, które zestawy danych zostały użyte do postawienia diagnozy, i wskazać źródła informacji.
Zapewniając przejrzysty zapis przebiegu danych od wejścia do wyjścia, wgląd w pochodzenie danych pozwala organizacjom zweryfikować źródło i wykorzystanie zestawów danych, sprawiając, że modele AI opierają się na dokładnych danych. Śledząc dane na każdym etapie przetwarzania, informacje na temat ich pochodzenia umożliwiają pełną kontrolę nad systemami AI i zapewniają zarówno ścisłą zgodność z przepisami, jak i wewnętrzną rozliczalność. Dyski twarde umożliwiają prześledzenie pochodzenia danych poprzez bezpieczne przechowywanie każdej transformacji, pozwalając deweloperom na przeglądanie historycznych rekordów danych, które ujawniają pełny zakres procesów decyzyjnych związanych z AI.
Uzasadnienie: wyjaśnienie procesu podejmowania decyzji przez sztuczną inteligencję.
Możliwość uzasadnienia sprawia, że decyzje podejmowane przez sztuczną inteligencję są zrozumiałe i ugruntowane w danych, które można śledzić i oceniać. Jest to szczególnie ważne w branżach o znaczeniu krytycznym, takich jak opieka zdrowotna i finanse, gdzie zrozumienie powodów, dla których podejmuje się decyzje w ramach sztucznej inteligencji, może wpływać na życie i inwestycje. Zachowując punkty kontrolne, dyski twarde pozwalają programistom spojrzeć wstecz na różne etapy rozwoju modelu, pozwalając im ocenić, jak zmiany w danych wejściowych lub konfiguracjach wpływają na wyniki. Dzięki takiemu podejściu systemy AI stają się bardziej przejrzyste i zrozumiałe, przyczyniając się do zwiększenia zaufania i użyteczności.
Rozliczalność: umożliwianie kontroli przepływów pracy związanych z AI.
Rozliczalność w sztucznej inteligencji sprawia, że modele mogą być badane i weryfikowane przez interesariuszy. Poprzez wyznaczanie punktów kontrolnych i śledzenie pochodzenia danych dyski twarde zapewniają ścieżkę audytu, która dokumentuje rozwój sztucznej inteligencji, począwszy od wprowadzania danych, aż po ich wyprowadzenie, umożliwiając organizacjom weryfikację czynników, które mają wpływ na decyzje podejmowane przez sztuczną inteligencję. Ta ścieżka audytu pomaga organizacjom zachować zgodność z przepisami i daje użytkownikom pewność, że systemy AI opierają się na niezawodnych i powtarzalnych procesach. Rozliczalność umożliwia wskazanie określonych punktów kontrolnych, w których podejmowano decyzje, co sprawia, że systemy AI są odpowiedzialne za swoje działania.
Bezpieczeństwo: ochrona integralności danych.
Bezpieczeństwo stanowi podstawę niezawodnej sztucznej inteligencji, chroniąc dane przed nieautoryzowanym dostępem i naruszeniem. Bezpieczne rozwiązania pamięci masowej, w tym szyfrowanie i sprawdzanie integralności, sprawiają, że modele AI bazują na autentycznych i niezmienionych danych. Dyski twarde wspierają zabezpieczenia poprzez przechowywanie danych w stabilnym, kontrolowanym środowisku, pomagając organizacjom zapobiegać ingerencji i zapewniając zgodność z rygorystycznymi przepisami w zakresie bezpieczeństwa. Zabezpieczając dane na każdym etapie procesu AI, firmy mogą zachować zaufanie do integralności przepływów pracy związanych z AI.
Mechanizmy zapewniające godną zaufania sztuczną inteligencję.
Osiągnięcie tych elementów godnej zaufania sztucznej inteligencji opiera się na niezawodnych mechanizmach, które wspierają integralność danych, bezpieczeństwo i rozliczalność. Począwszy od określania punktów kontrolnych i polityk zarządzania, aż po haszowanie i systemy pamięci masowej, narzędzia te sprawiają, że systemy AI spełniają wysokie standardy potrzebne do niezawodnego podejmowania decyzji. Poniżej omawiamy, w jaki sposób te mechanizmy stanowią podstawę godnej zaufania sztucznej inteligencji.
Punkty kontrolne: obsługa wielu elementów.
Tworzenie punktów kontrolnych to proces zapisywania stanu modelu AI w określonych, krótkich odstępach czasu podczas jego trenowania. Modele AI są trenowane na dużych zbiorach danych w iteracyjnych procesach, które mogą trwać od kilku minut do dni.
Punkty kontrolne działają jak migawki obecnego stanu modelu – jego danych, parametrów i ustawień – w wielu punktach podczas trenowania. Zapisywane na urządzeniach pamięci masowej migawki co minutę lub kilka minut pozwalają programistom zachować rejestr postępów modelu i uniknąć utraty cennej pracy z powodu nieoczekiwanych zakłóceń.
Punkty kontrolne umożliwiają korzystanie z godnej zaufania sztucznej inteligencji, spełniając kilka krytycznych funkcji:
Ochrona przed utratą zasilania. Punkty kontrolne zabezpieczają zadania związane z trenowaniem przed awariami systemu, przerwami w zasilaniu lub awariami, pozwalając modelom na wznawianie pracy od ostatniego zapisanego stanu bez konieczności zaczynania od zera.
Poprawa i optymalizacja modelu. Zapisując punkty kontrolne, programiści mogą analizować stany z przeszłości, dostosowywać parametry modelu i zwiększać wydajność w dłuższym okresie.
Zgodność z przepisami prawa i ochrona własności intelektualnej. Punkty kontrolne zapewniają przejrzysty zapis, który pomaga organizacjom zachować zgodność z przepisami prawa i chronić zastrzeżone metodologie.
Budowanie zaufania i zapewnianie przejrzystości. Punkty kontrolne rejestrują stany modelu, ułatwiając wyjaśnianie poprzez podejmowanie decyzji związanych z AI, które są możliwe do prześledzenia i zrozumienia.
Polityki zarządzania: kierowanie odpowiedzialnym zarządzaniem danymi.
Polityki w zakresie zarządzania określają ramy, w ramach których prowadzone jest zarządzanie danymi, dane są chronione i wykorzystywane w całym cyklu życia sztucznej inteligencji. Te polityki gwarantują, że systemy AI są zgodne z wymogami regulacyjnymi i wewnętrznymi standardami, tworząc środowisko, w którym dane są obsługiwane w sposób etyczny i bezpieczny. Polityki zarządzania definiują kontrolę dostępu, harmonogramy przechowywania danych oraz procedury zapewniania zgodności, wspierając w ten sposób bezpieczeństwo oraz rozliczalność w ramach procesów produkcyjnych wykorzystujących sztuczną inteligencję. Określając te standardy, organizacje mogą zapewnić przejrzystość i niezawodność systemów AI, które opierają się na solidnych zasadach zarządzania danymi.
Haszowanie: zabezpieczenie pochodzenia danych
Haszowanie odgrywa kluczową rolę w utrzymaniu możliwości śledzenia pochodzenia danych poprzez tworzenie unikatowych cyfrowych „odcisków palców” dla danych. Te „odciski palców” pozwalają organizacjom zweryfikować, czy dane nie zostały zmienione lub naruszone na dowolnym etapie procesu związanego z AI. Poprzez haszowanie zbiorów danych i punktów kontrolnych, systemy AI są w stanie zapewnić spójność i nienaruszalność wprowadzanych danych, zwiększając bezpieczeństwo i przyczyniając się do rozwoju przejrzystości. Dyski twarde przechowują te haszowane rekordy zaszyfrowanych danych, umożliwiając organizacjom weryfikację autentyczności danych i utrzymanie zaufania do przepływów pracy związanych ze sztuczną inteligencją.
Systemy pamięci masowej o dużej pojemności: umożliwiające skalowalne i bezpieczne przechowywanie danych.
Systemy pamięci masowej, a zwłaszcza te, które wykorzystują dyski twarde, zapewniają podstawową pojemność potrzebną do przechowywania i zarządzania dużymi ilościami danych, które są niezbędne w przypadku godnej zaufania sztucznej inteligencji.
Dyski twarde oferują skalowalną i wydajną pod względem kosztów pamięć masową, która zapewnia systemom AI dostęp zarówno do aktualnych, jak i archiwalnych danych. Te systemy zapewniają przejrzystość, utrzymując dostępną dokumentację, możliwość uzasadnienia, zachowując dane na przestrzeni czasu, oraz bezpieczeństwo poprzez zapewnianie stabilnych środowisk pamięci masowej danych.

Seria dysków twardych Seagate Exos® z technologią Mozaic 3+™ jest przeznaczona specjalnie do zastosowań tego typu. Dyski te przechowują nieprzetworzone zestawy danych, które są podstawą dla modeli AI, szczegółową dokumentację procesów generowania danych, iteracyjne punkty kontrolne w trakcie trenowania modelu oraz wyniki analiz AI.
Dyski twarde odgrywają istotną rolę w zapewnianiu przejrzystości, przechowując ogromne zbiory danych i inne informacje o znaczeniu krytycznym wykorzystywane w modelach AI. Dane te są łatwo dostępne dzięki połączeniu sieciowych dysków twardych przeznaczonych do długoterminowego przechowywania danych oraz dysków SSD z natychmiastowym dostępem. Pozwala to organizacjom śledzić każdy punkt decyzyjny w cyklu życia sztucznej inteligencji.
Skrupulatna dokumentacja rejestrowana na dyskach twardych służy zachowaniu ścisłej zgodności z przepisami, zwiększa przejrzystość, umożliwia doskonalenie modelu i przyczynia się do większej rozliczalności. Dyski twarde dokumentują pełny cykl życia danych, dostarczając przejrzystą dokumentację, którą można przeglądać w celu weryfikacji zgodności z przepisami i zasadami.
Ilość danych z różnych dziedzin stale wzrasta. W medycynie takie dziedziny jak badania nad genomiką i obrazowanie medyczne generują petabajty danych rocznie. Urządzenia IoT, w tym czujniki i podłączone do sieci gadżety, a także eksplozja treści generowanych przez użytkowników w mediach społecznościowych znacząco przyczyniają się do tego potopu danych.
Dyski twarde stały się kosztowo efektywną i skalowalną opcją pamięci masowej. Oferują one dużą pojemność pamięci masowej przy najniższym koszcie na terabajt (6:1 w porównaniu do pamięci flash), co sprawia, że stanowią optymalny wybór na długoterminowe przechowywanie danych. Dlatego właśnie dyski twarde są idealnym rozwiązaniem do przechowywania ogromnych zbiorów nieprzetworzonych danych używanych do przetwarzania AI i przechowywania wyników analizy AI. Oprócz zabezpieczania długookresowego przechowywania danych wejściowych i wyjściowych dyski twarde obsługują również przepływy pracy związane z AI na etapie trenowania wymagającego dużej mocy obliczeniowej, umożliwiając śledzenie punktów kontrolnych i zapisywanie różnych iteracji treści.
Podsumowanie.
Droga do niezawodnej sztucznej inteligencji prowadzi przez przejrzystość, pochodzenie danych, uzasadnienie, rozliczalność i bezpieczeństwo. Te elementy pozwalają organizacjom przekształcać dane z prostych liczb w godne zaufania innowacje.
Droga do niezawodnej sztucznej inteligencji prowadzi przez przejrzystość, pochodzenie danych, uzasadnienie, rozliczalność i bezpieczeństwo. Te elementy pozwalają organizacjom przekształcać dane z prostych liczb w godne zaufania innowacje.
Obsługując cały proces przepływu danych AI – od rejestracji nieprzetworzonych danych aż po przechowywanie punktów kontrolnych i wyników analizy – dyski twarde odgrywają kluczową rolę w walidacji, dostrajaniu i budowaniu zaufania do modeli AI. Wykorzystując dyski twarde do długoterminowego przechowywania danych, deweloperzy AI mogą wrócić do wcześniejszych wersji treningowych, analizować wyniki i dostosowywać modele w celu poprawy wydajności i dokładności.
W miarę poszerzania zakresu sztucznej inteligencji na kolejne sektory, kluczowe staje się pochodzenie danych, przestrzeganie standardów regulacyjnych i czytelna komunikacja z interesariuszami. Inżynierowie z firmy Seagate stworzyli dyski twarde jako skalowalne, efektywne kosztowo rozwiązania pamięci masowej do zaspokojenia tych potrzeb. W efekcie deweloperzy wykorzystujący sztuczną inteligencję mogą je stosować do konstruowania inteligentnych i niezawodnych systemów.







