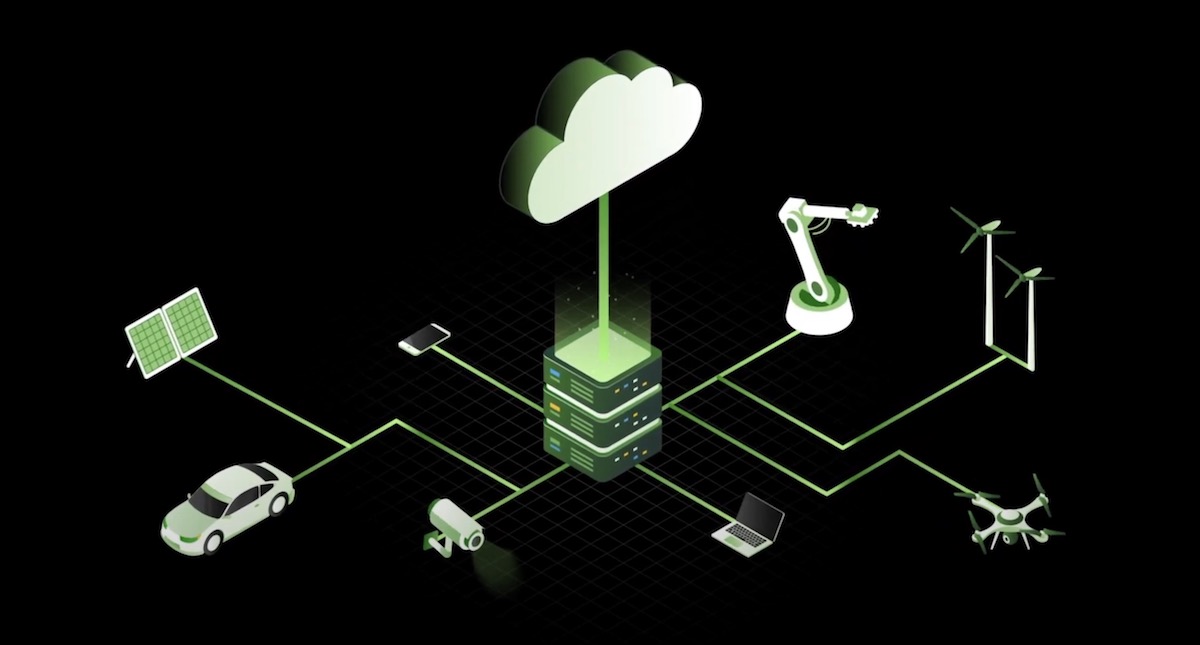
The race is on to bring driverless cars into commercial use by 2022. Data at the edge enabled by the emerging IT 4.0 infrastructure will play a major part in ensuring not only that they hit this target, but also that the vehicles that make the cut are safe enough to earn widespread public confidence.
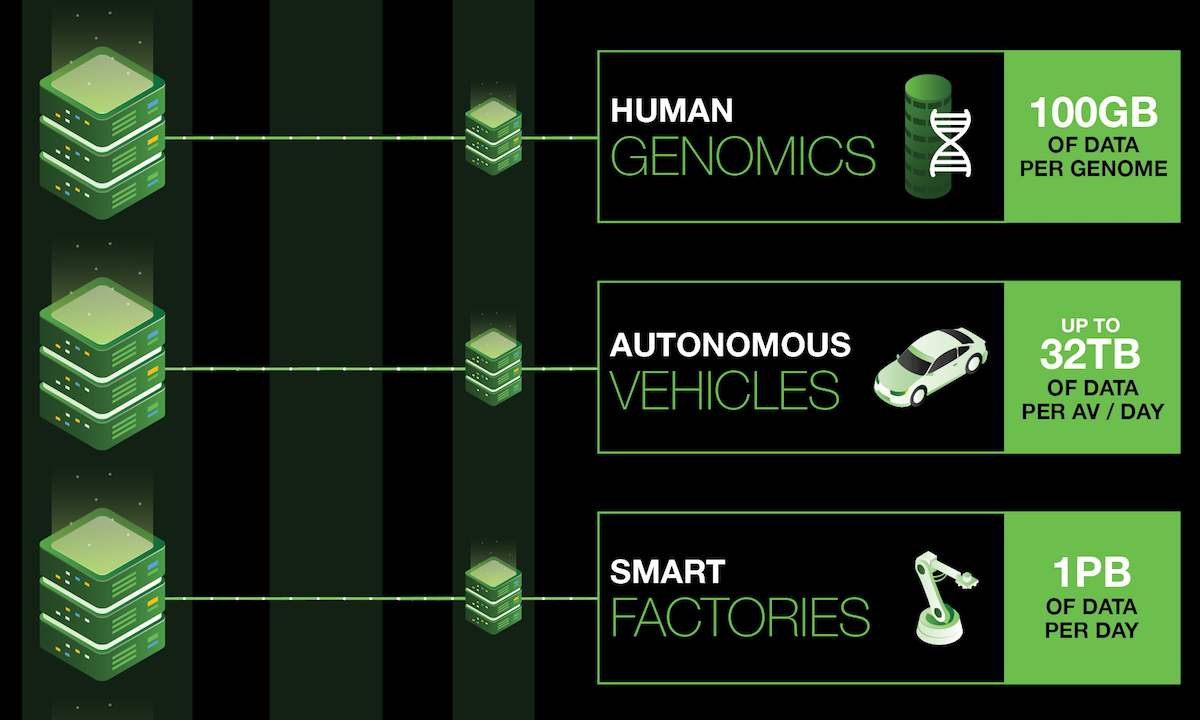
Driverless cars are packed so full of sensors and cameras that they each generate terabytes of data every day. For a vehicle’s onboard artificial intelligence (AI) agents to safely and effectively use this data, they must be able analyze and act on it in real-time — to instantly crunch through the essential information on-board, while also retaining the non-critical data for later processing on external edge or cloud servers.
This much data analysis creates a challenge
Even human-controlled cars are increasingly data-heavy. A new car today might have anywhere from 25-50 CPUs on board to handle functions such as cruise control, blind-spot vision, collision warnings, and automated breaking. Many of these systems share data with each other via an on-board network.
Driverless cars take advantage of edge computing in which data is processed on-board. In addition to driving assistance systems, they have myriad computer-vision, mapping, routing, and communications systems. In a speech where he suggested data has become “the new oil,” former Intel CEO Brian Krzanich said that a typical driverless car might create around 4,000 GB of data a day.
Moreover, Evangelos Simoudis, managing director of venture capital firm Synapse Partners, noted in a roundtable discussion on data and the future of autonomous vehicles, that the scale of this data generation is “stupendous.” And it presents a challenge for automakers who hope to use it to bring automated driving to the masses.
Latency may become a life or death factor
All the data for self-driving cars just can’t be processed in the cloud. That introduces too much latency. Even a 100 millisecond delay — faster than the blink of an eye — could mean the difference between life and death for a passenger or pedestrian. These vehicles must sense, think, and act as quickly as possible.
To minimize the time between sensing and acting, at least some of the data needs to be analyzed on-board, in-car. That’s where edge data analysis — a kind of data processing at the outer nodes of a network — comes into play. Driverless cars are part of a complex hybrid network that combines centralized data centers with lots of smaller edge data centers — including other autonomous and semi-autonomous vehicles, roadside gateways and sensor hubs, charging stations, traffic control boxes, and other connected devices.
Out-of-vehicle data centers help to give driverless cars a broader context. They allow the cars to “see” beyond their sensor range, to coordinate traffic flows with other vehicles, and to aid in complex decision making — a kind of AI-powered alternative to hand signals, radio, and smartphone navigation apps, such as Waze and OpenStreetMap.
Similarly, just as a human driver might make a mental note of something unexpected — such as a pothole — to prepare them for future encounters, a driverless car needs to draw lessons from its experiences. According to a report in Data Center Knowledge, many driverless cars will do this by dumping their data into edge data centers embedded in charging stations.
The charging stations could then use deep learning AI algorithms to do the heavy-lifting on data analysis and transfer the resulting knowledge not only to that driverless car, but also up to the cloud so that it can be passed along to every other driverless car on the network.
If that data sharing is multiplied out across all driverless cars — given projections that range from several hundred thousand to tens of millions of them by 2025 — the data footprint could be in the exabytes (millions of terabytes) per day. Stupendous, indeed.
Today, driverless cars are already gathering huge amounts of data, not only in public trials and private testing facilities around the world but also in virtual worlds.
Virtual pedestrians and simulated roads help pave the way
It’s too dangerous to test driverless vehicles using unusual driving scenarios in the real world, and manufacturers have been hyper-cautious since the first pedestrian fatality involving an autonomous test car in March 2018. In order to make driverless AI smarter — without risking damage to life, limb, property or public goodwill — much of the testing now happens away from public roads.
A Reuters report notes that Volvo is one of many manufacturers testing its self-driving cars on private tracks that use dummies and other props to mirror real-world driving conditions without putting any lives at risk. The report adds that trucking companies like Scania have also been experimenting with driverless truck testing in private, enclosed sites like warehouses and mines.
Self-driving technology is also being put through its paces in computer simulations, notes an MIT Technology Review report. One simulation by Waymo, for example, includes 25,000 cars driving a collective 10 million miles a day around a perilous virtual world that presents scenarios much too dangerous to test in the real world.
The massive amount of data gathered by these virtual world tests will be essential for training driverless car AI to be as robust as possible ahead of larger real-world rollouts. But by nature of the way these vehicles learn through direct experience rather than broader context, the MIT Technology Review’s story noted that self-driving cars needed many billions more miles of both real and virtual test driving to be reliably safe in unexpected situations.
That corresponds to a dizzying amount of data, but it’s all critical to a successful public rollout of the technology. Once driverless cars are available to the public, they will continue to depend on a mix of in-car data collection and processing — to manage the sensing, thinking, and acting that all drivers must do — combined with deeper learnings derived from other edge and cloud data sharing and analysis.
This proliferation of data analysis at the edge is the dawn of the IT 4.0 era — the new IT infrastructure paradigm that transforms data from passive to active. Edge computing will enable processing of data at or near where it is collected, rather than on a cloud server, so analysis and answers can be provided much more quickly to make decisions and solve issues immediately. Terabytes of data, every day, enabling driverless car communication and — with sufficient and rapid analysis — helping keep roads free from accidents.